Yuu Jinnai
Home
Google Scholar
GitHub
Current Research:
Minimum Bayes Risk Decoding
Language Model Alignment
Prior Projects:
Parallel Best-First Search
Automated Skill Discovery
日本語:
Japanese
Open Data Structures
ヒューリスティック探索入門
Hosted on GitHub Pages — Theme by orderedlist
Language Model Alignment
Language model alignment aims to ensure that large language models (LLMs) behave in ways that are helpful, harmless, and aligned with human values and preferences. My research develops efficient and robust methods for aligning LLMs.
Overview
Modern LLMs are pre-trained on massive text corpora but require additional alignment to follow instructions accurately and avoid harmful behaviors. My work addresses key challenges in alignment such as annotation efficiency, reward hacking, evaluation methodology, and cultural sensitivity.
Contributions
Annotation-Efficient Preference Optimization

Problem: Preference optimization methods like DPO require large amounts of expensive human preference annotations, making alignment costly and time-consuming.
Solution: We developed annotation-efficient preference optimization (AEPO), which strategically selects the most informative samples for annotation, reducing annotation costs by up to 75% while maintaining alignment quality.
Publication: Jinnai Y, Honda U. 2025. Annotation-Efficient Preference Optimization for Language Model Alignment. In Findings of the Association for Computational Linguistics (EMNLP-25 Findings).
PAPER | CODE | TALK
Regularized Best-of-N Sampling

Problem: Best-of-N (BoN) sampling can exhibit reward hacking, where models exploit weaknesses in reward models to achieve high scores without genuine alignment.
Solution: We proposed regularized BoN sampling that incorporates a Minimum Bayes Risk objective to prevent reward hacking while maintaining alignment quality, providing a more robust inference-time alignment method.
Publication: Jinnai Y, Morimura T, Ariu K, Abe K. 2024. Regularized Best-of-N Sampling with Minimum Bayes Risk Objective for Language Model Alignment. North American Chapter of the Association for Computational Linguistics (NAACL-25).
PAPER | CODE | TALK
Evaluation of Best-of-N Sampling Strategies

Problem: Multiple BoN sampling variants exist, but comprehensive evaluation and understanding of their trade-offs has been lacking.
Solution: We conducted a systematic evaluation of BoN sampling strategies, identifying which methods work best under different conditions and providing practical guidance for practitioners.
Publication: Ichihara Y, Jinnai Y, Morimura T, Ariu K, Abe K, Sakamoto M, Uchibe E. 2025. Evaluation of Best-of-N Sampling Strategies for Language Model Alignment. Transactions on Machine Learning Research (TMLR).
PAPER | CODE | TALK
Filtered Direct Preference Optimization
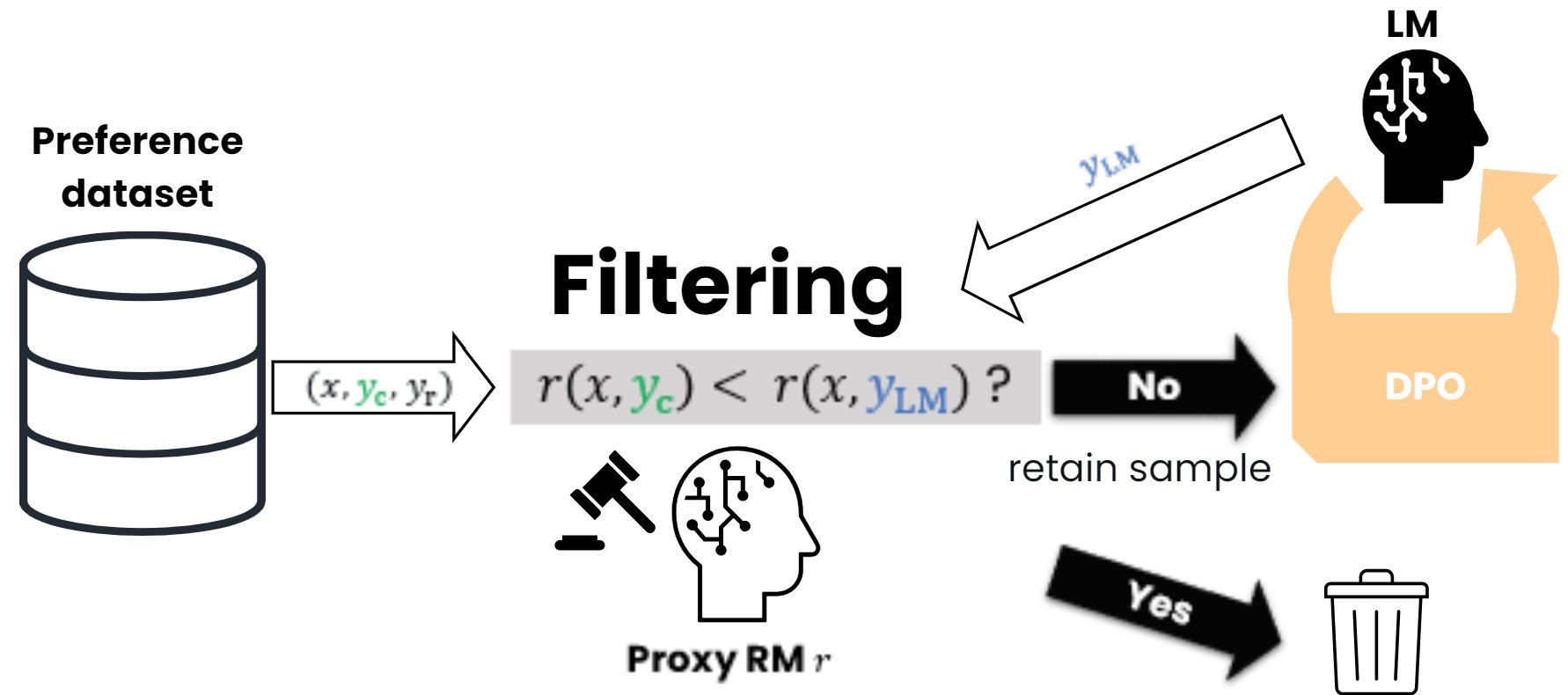
Problem: Direct Preference Optimization (DPO) can be sensitive to noisy or low-quality preference pairs in training data, degrading alignment performance.
Solution: We developed filtered DPO, which automatically identifies and filters out unreliable preference pairs during training, improving robustness and final model quality.
Publication: Morimura T, Sakamoto M, Jinnai Y, Abe K, Ariu K. 2024. Filtered Direct Preference Optimization. The 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP-24).
PAPER | CODE
Cross-Cultural Alignment and Commonsense Morality

Problem: Most LLM alignment research focuses on English and Western values. How alignment affects commonsense morality across different cultures remains unclear.
Solution: We investigated whether cross-cultural alignment changes the commonsense morality of language models, demonstrating that cultural context significantly impacts model behavior and highlighting the need for culturally-aware alignment.
Publication: Jinnai Y. 2024. Does Cross-Cultural Alignment Change the Commonsense Morality of Language Models? Proceedings of the 2nd Workshop on Cross-Cultural Considerations in NLP (C3NLP Workshop at ACL 2024). 🏆 Best Paper Award
PAPER | TALK | MODEL | DATASET
All Alignment Publications
- Jinnai Y, Honda U. 2025. Annotation-Efficient Preference Optimization for Language Model Alignment. EMNLP-25 Findings.
- Jinnai Y, Morimura T, Ariu K, Abe K. 2024. Regularized Best-of-N Sampling with Minimum Bayes Risk Objective for Language Model Alignment. NAACL-25.
- Ichihara Y, Jinnai Y, Morimura T, Ariu K, Abe K, Sakamoto M, Uchibe E. 2025. Evaluation of Best-of-N Sampling Strategies for Language Model Alignment. TMLR.
- Morimura T, Sakamoto M, Jinnai Y, Abe K, Ariu K. 2024. Filtered Direct Preference Optimization. EMNLP-24.
- Jinnai Y. 2024. Does Cross-Cultural Alignment Change the Commonsense Morality of Language Models? C3NLP Workshop at ACL 2024. Best Paper Award.
Software and Code
All code is publicly available on GitHub:
- Annotation-Efficient Preference Optimization
- Regularized Best-of-N Sampling
- BoN Sampling Evaluation
- Filtered DPO
Resources
- Models: CALM2-7B-Chat-DPO
- Datasets: Japanese Chatbot Arena